The DistinctCount and its rough edges
This is a follow-up on my last distinct count post. I’m going to show you the performance difference and the other aspects that you should bear in mind while projecting the distinct count KPIs.
Performance
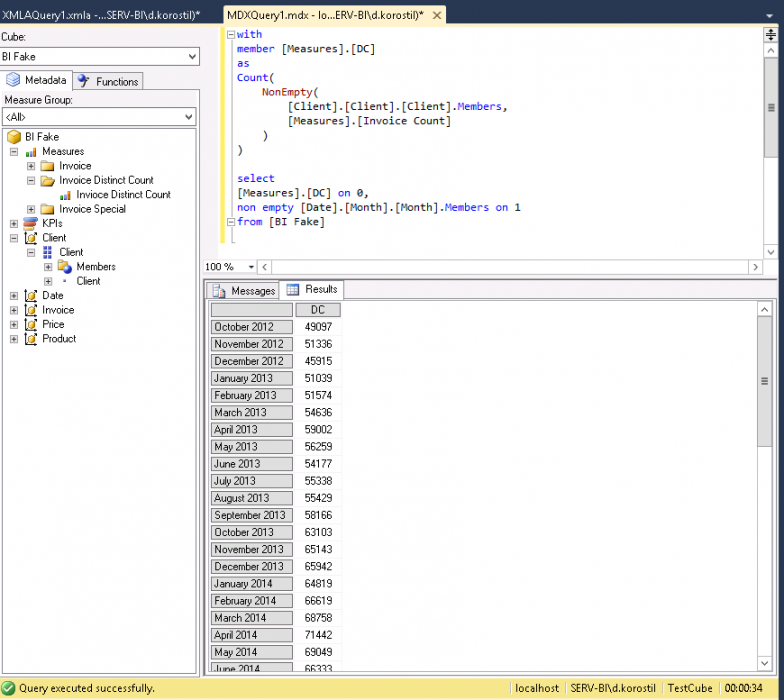
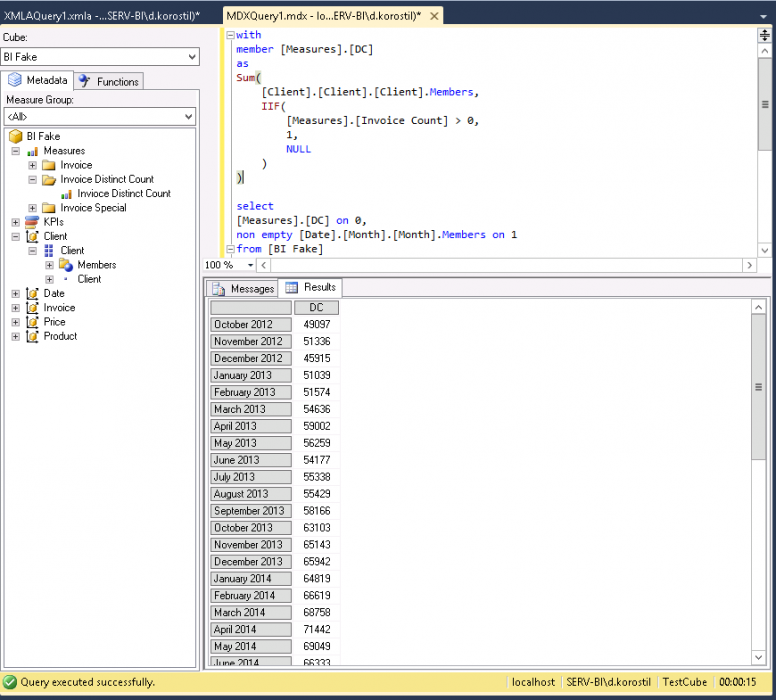
For example, you want to count customers who are having invoices on the monthly basis. My test will cover three cases for both cold and warm runs:
- Sum(Count(…))
- Sum(IIF(…))
- Native DC
1-Cold:
1-Warm:

2-Cold:
2-Warm:
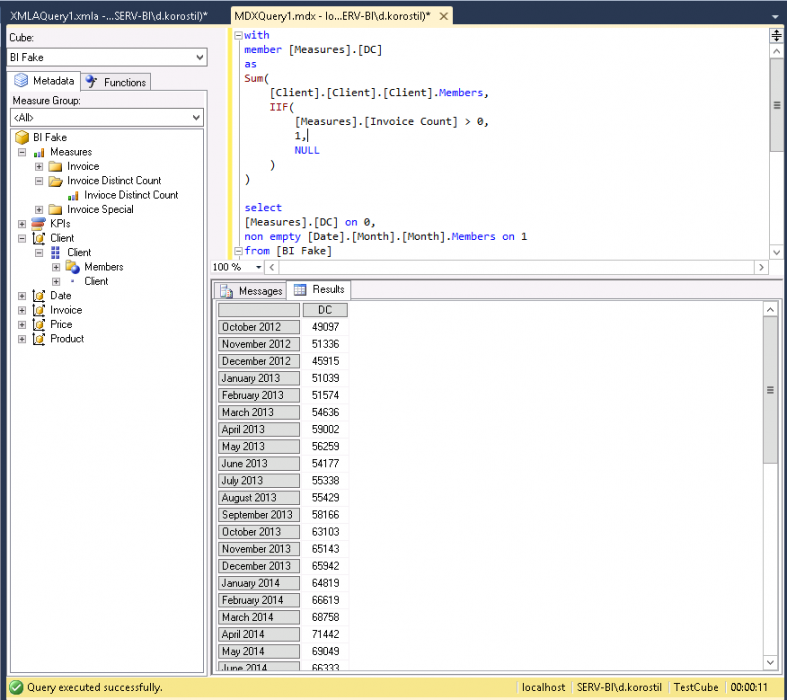
3-Cold:
3-Warn:

Numbers aren’t that precise because they depend on side factors and cases. Nonetheless, you could have mentioned that the native measure caching is really good.
The Existing case
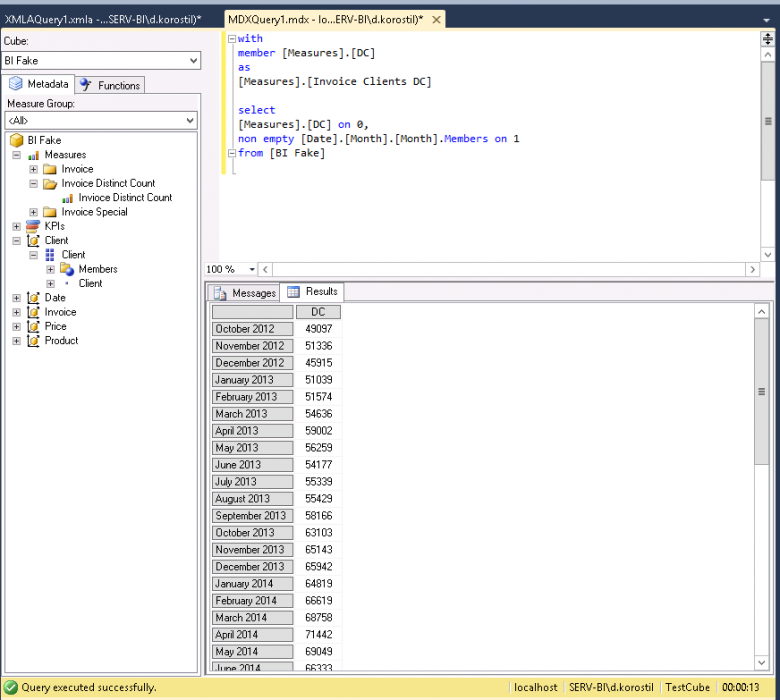
If you drill down to client axis while using the client hierarchy in MDX it will return something unexpected:
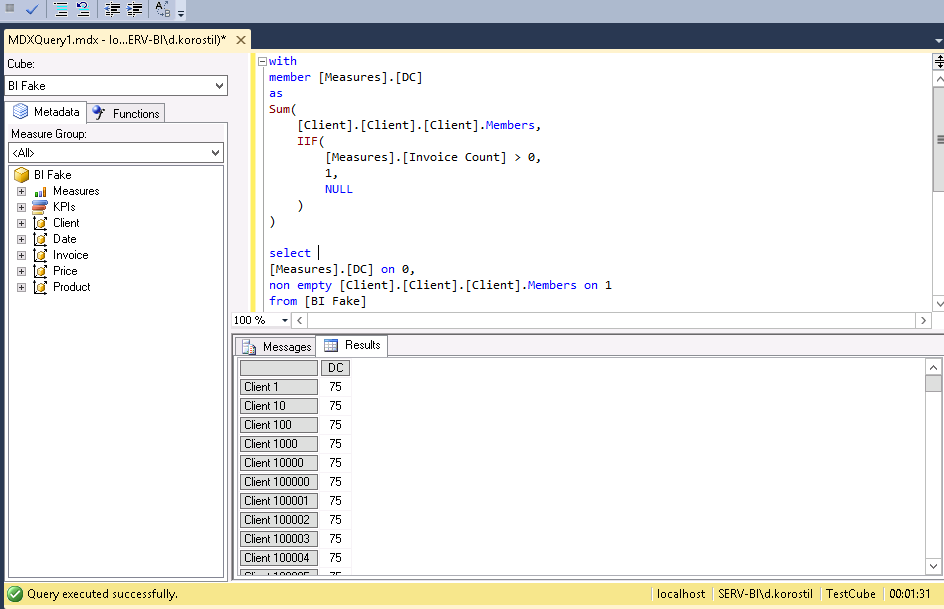
The native DC works properly:
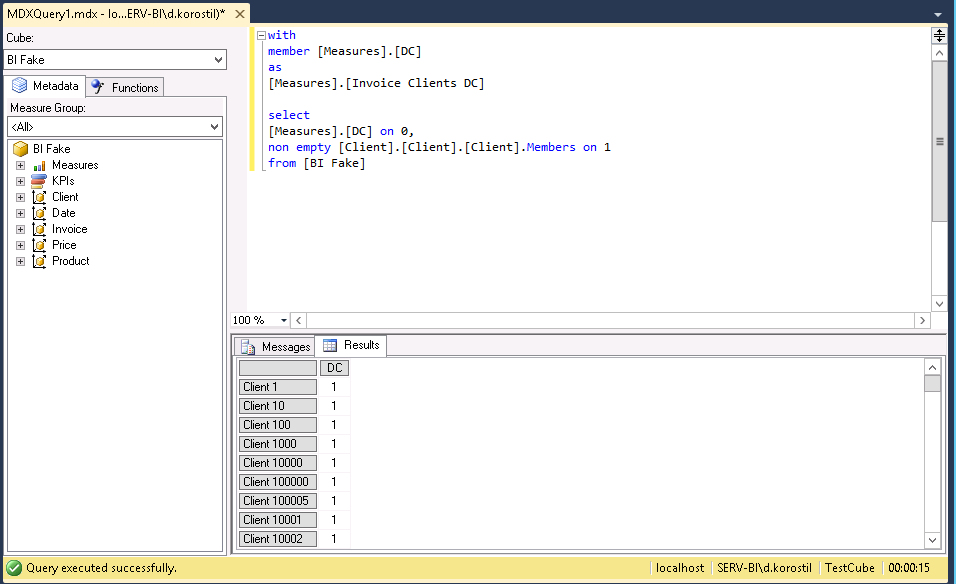
Why does that happen? Let’s say your current member is Client1 and MDX forces itself to list every single client and perform the calculation, resulting in the following member being overridden with a new one from the client hierarchy.
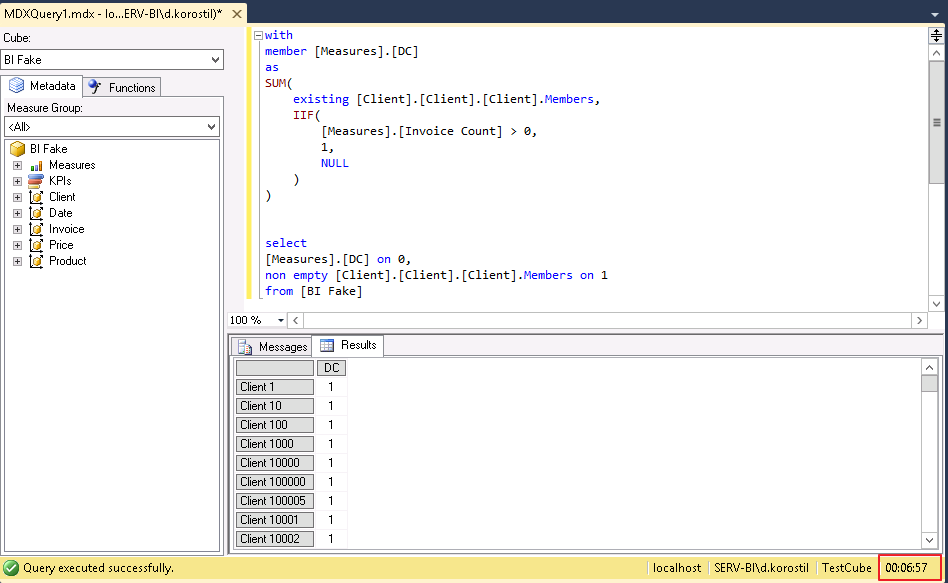
How to avoid that? Use Existing function before the set. But it’s too slow:
How to speed that up? You may add new attribute hierarchies just like your key:
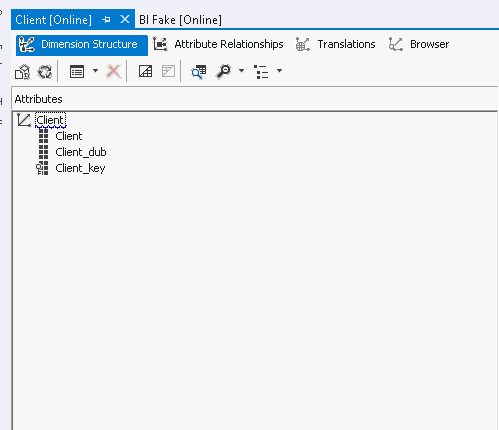
- Client_key – is a dimension key.
- Client – is a regular attribute containing id and name of client.
- Client_dub – is a duplicate of the key, but not actually the key.
MDX will behave differently with different sets you put into the formula:
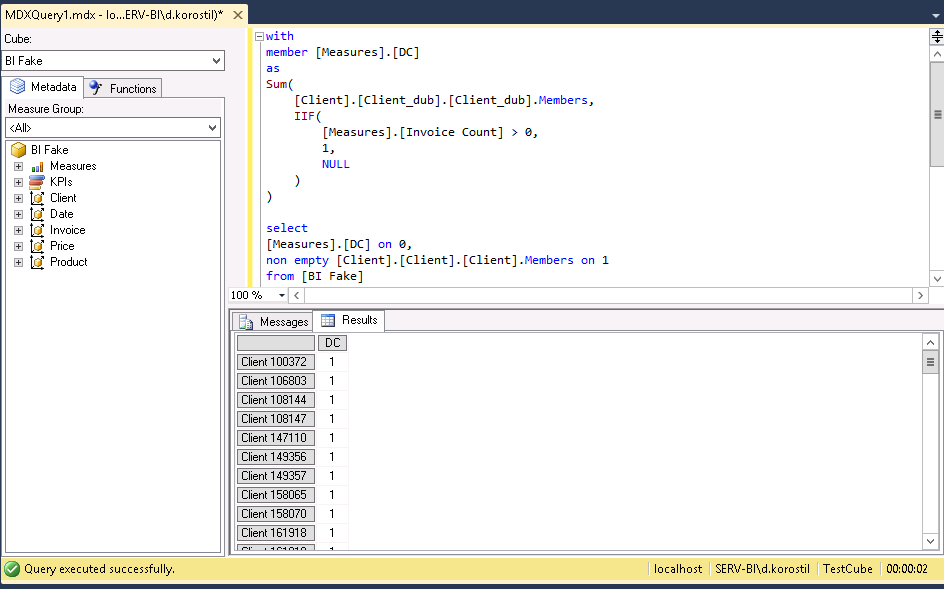
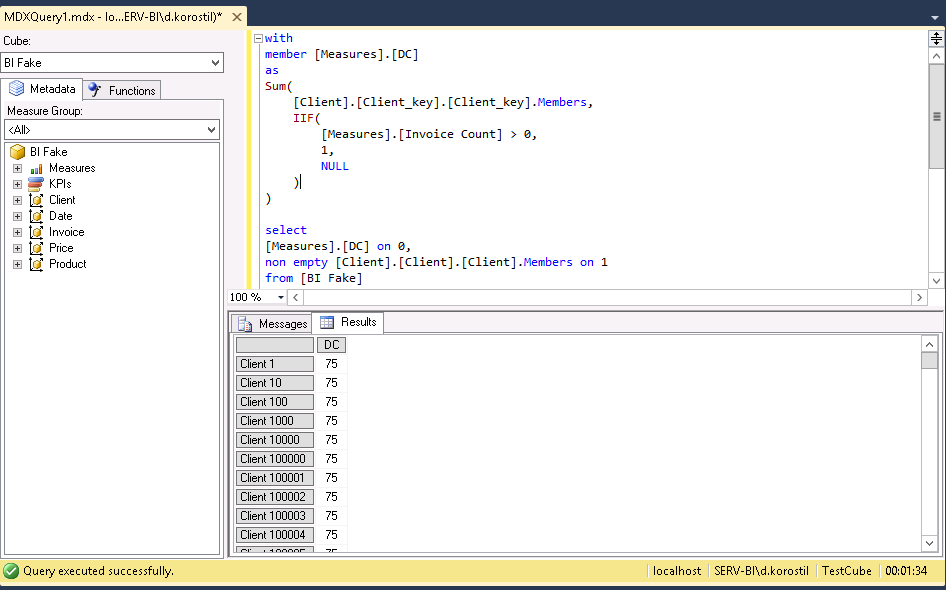
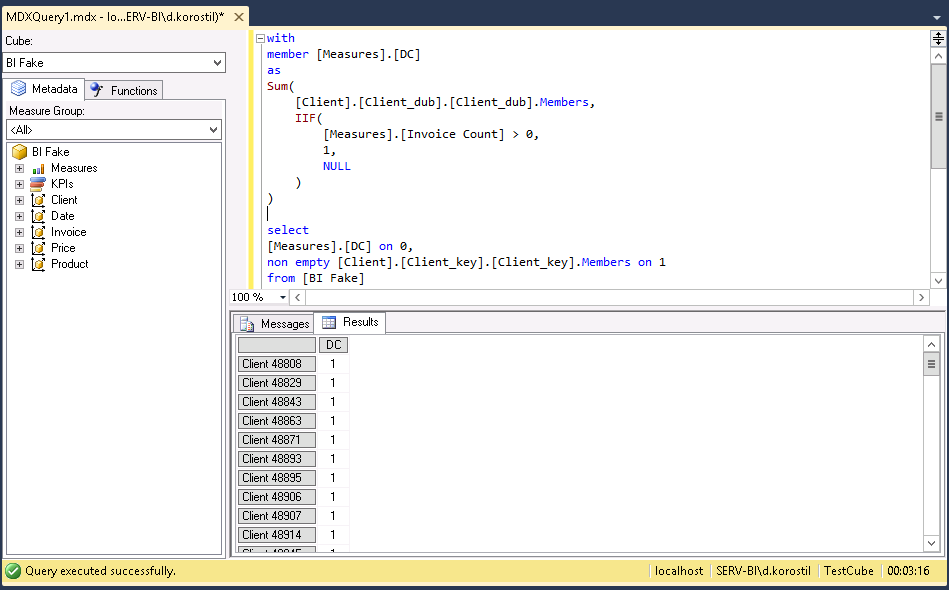
It may appear weird to you, but my recommendations are:
- Never use the primary key within the MDX calculations.
- Try to avoid using a set that may appear on axis.
- Hide your primary key from the user, add an extra one.
- Don’t you existing keyword, if it’s possible.
Conclusion
The more you calculate in DWH the faster your cube queries work. I’d recommend to pre-calculate as much as it possible. MDX doesn’t support an efficient concurrency, and due to its every-attribute-bound-to every-fact nature it’s not that flexible as pure SQL. Nonetheless, sometimes it’s very powerful and useful.
Hope, It’s helpful. Feel free to to ask questions.
-
SQL interview tasks #1
12 July 2020
-
How to speed up migration from local DB to Azure
19 November 2018
-
The dynamic members
24 March 2017
-
My name is Rank, Dense Rank!
14 March 2017
-
Web OLAP: Step one
27 December 2016
-
The DistinctCount and its rough edges
30 November 2016
-
Will the SSAS be ported to linux?
17 November 2016
-
The totals and the NonEmptyCrossJoin function
11 November 2016
-
The best DistinctCount practice in SSAS
17 October 2016
-
Generate row set recursively
13 September 2016